Recently I asked an LLM to recommend a good webcam – and after a few follow up questions it told me I didn’t need one. should just reorient my desk for better lighting. This got me thinking about how interactions with language models might change what we think about products and why we buy them. We live in a space where product messaging carefully crafted by marketers and distributed by systems selling our eyeballs to the highest bidder informs purchasing the decisions we make. How might this system be disrupted by the growing role language models are playing in the information spaces we inhabit?
Towards Measuring the Representation of Subjective Global Opinions in Language Models (2023, Anthropic)
A 2023 Study from Anthropic showing how LLMs opinions can differ from those of general human consensus.

A Simple Experiment
A 2023 study from Anthropic demonstrated how value judgments made by LLM’s can differ from those of human populations. I used a similar approach to understand how LLM’s might influence our product decisions. As as start I decided to try to answer two questions:
- How consistently do LLM’s recommend certain products over others?
- To what extent do recommendations differ between popular commercial LLM’s?
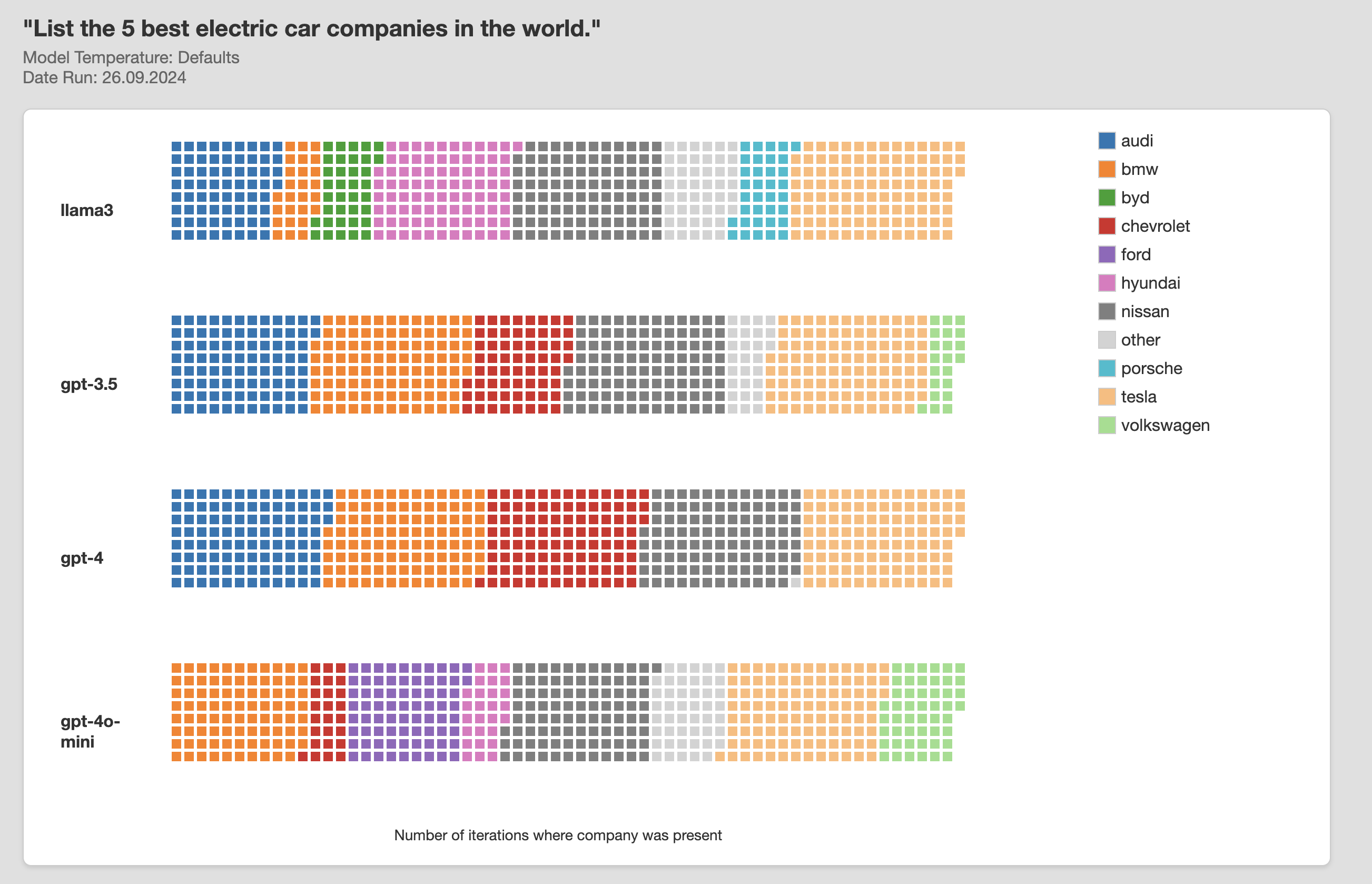
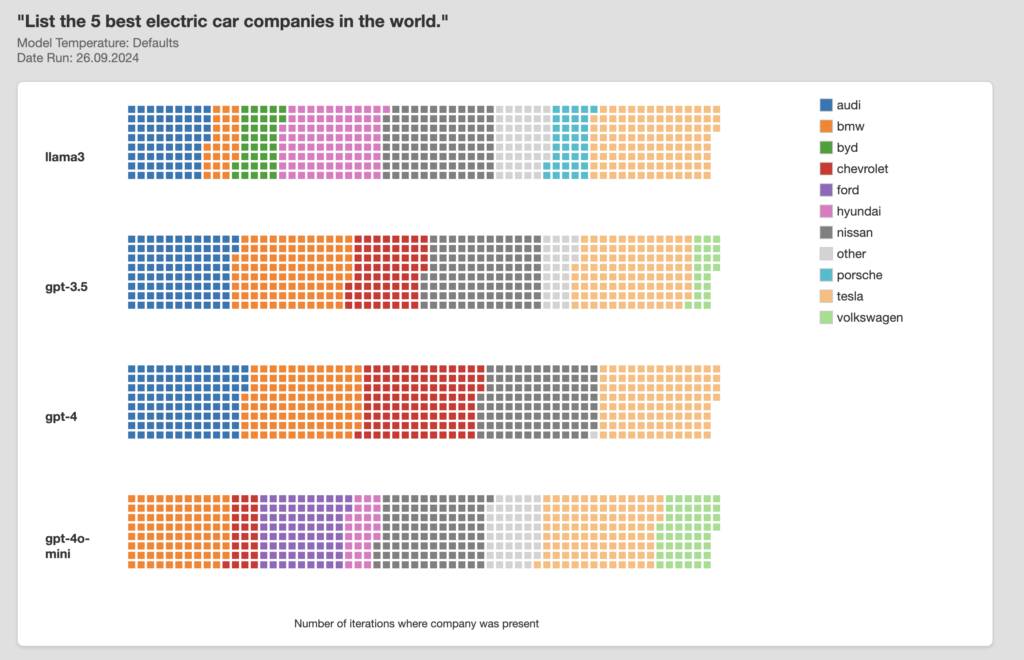
I wrote some code to automate submission of questions to different LLMs and visualise responses. Commercial LLM’s are typically used with non-zero temperature settings so I collected samples of responses from different LLM’S to capture their response distributions. Here’s an example of the output of looping the question: “List the 5 best electric car manufacturers in the world” 100 times through 4 different LLMs, resulting in a total of 2000 company names. Each small block below represents a single company name returned by a single model.
Here’s the same exercise with a different question: “what are top 5 factors that make a good electric car”.
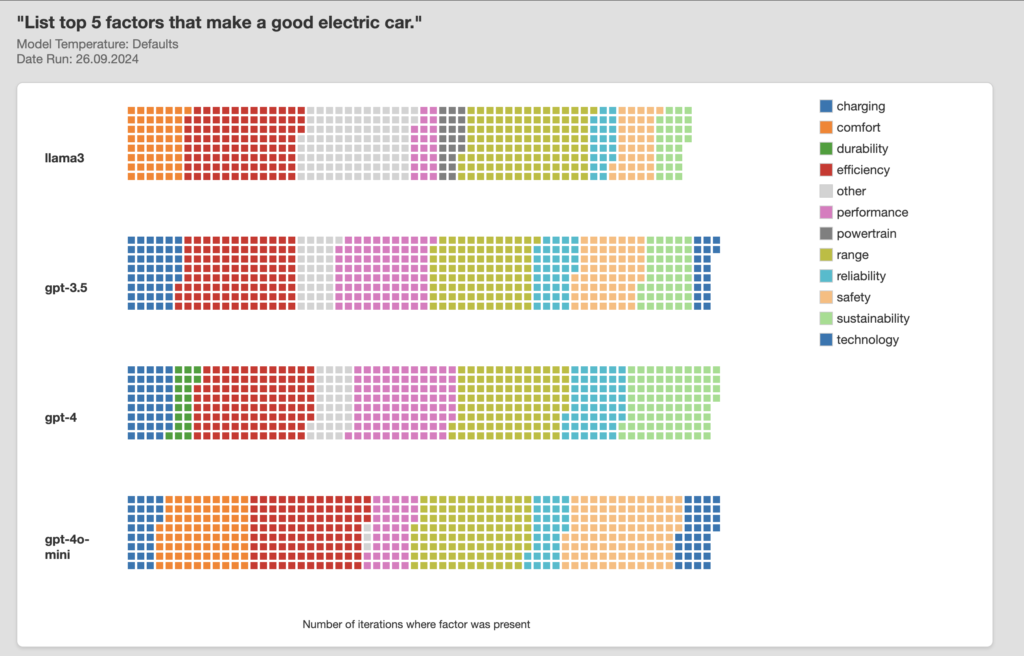
Its not really surprising – that different models provide different distributions of answers. They were trained on unique data sets, generated at different times using differing algorithms. It is interesting though to consider that if I use GPT4 to do product research and you use GPT4o mini, our mental models of the world may start to diverge in ways that can be predicted by the biases of each llm. Many of today’s tech companies make money through advertising. It’s not really clear yet how financial incentives might drive manipulation of LLM’s at a system level – but if the multi billion dollar SEO industry is anything to go by this could become a lucrative industry.
Follow up Study
Most interactions people have with LLM’s are multi-turn conversations rather than requests for discreet lists. The next stage of the research is to replicate it on large samples of simulated conversations with LLM’s to understand whether biases discovered through list-type questions persist in multi-turn conversations. . Note: If you’re interested in trying this out here’s the link the the repo with the (very) rough code. It’s a Jupyter notebook using Python to fetch the data and D3. to visualise the results. I use a local version of Llama3 via Ollama and a private key for the OpenAI API access.



